This blog post contains some excellent wireframe resources:
http://www.noupe.com/design/35-excellent-wireframing-resources.html
Java DevOps engineer / Scrum Master
This blog post contains some excellent wireframe resources:
http://www.noupe.com/design/35-excellent-wireframing-resources.html
On WDL the present an excellent overview of some of the best wireframe tools that you can find: http://webdesignledger.com/tools/10-excellent-tools-for-creating-web-design-wireframes
In this article I’ll explain how to auto start Fisheye/Crucible. Earlier today I wrote an article about how to auto start Jira, Crowd and Confluence using a dedicated (non root) user after rebooting the system. Jira, Crowd and Confluence have Apache Tomcat ‘built in’. Unfortunately there are some differences between the way how Atlassian products are set up. Fisheye does not come with Tomcat, which means it is a bit more difficult to get things going.
The first problem we encountered was binding to port 80. It is quite easy to do this by editing the config.xml or using the admin console. However, you will run into the issue that only root users can use port 80. So it is best to leave the default port binding at 8060 and use a different approach with the iptables command.
First make sure that all ports that are required have been opened up in the firewall. Open port 80, 8060 and 8059 (control port).
system-config-securitylevel
Now add a ‘prerouting rule’ and save it. This rule will redirect all traffic from port 80 to port 8060. So you can use the URL http://fisheye and do not need to specify port 8060 (http://fisheye:8060). Use these two commands (first command is split in two lines, it is one line!).
iptables -t nat -A PREROUTING -p tcp –dport 80 -j REDIRECT –to-port 8060
/sbin/service iptables save
That taken care off we can now create our dedicated user and grant this user the ownership of the relevant folder (change folder name to match your own situation).
useradd -m fisheye
chown -R fisheye /opt/fecru-2.2.0
As we will add a Fisheye service we now create the service script. If you copy/paste be aware that some extra line-feeds may have been added, remove those. The script has been created using various sources and surely can be improved, I am no Linux guru!
nano /etc/init.d/fisheye
This is the content:
#!/bin/bash
# Crucible/Fisheye startup script
# chkconfig: 345 90 90
# description: Atlassian Crucible
CRUCIBLE_USER=fisheye
CRUCIBLE_HOME=/opt/fecru-2.2.0/bin
RETVAL=0
prog=crucibled
pidfile=/var/lock/subsys/crucibled
start() {
echo -n $”Starting $prog: “
if [ “x$USER” != “x$CRUCIBLE_USER” ]; then
su – $CRUCIBLE_USER -c “$CRUCIBLE_HOME/fisheyectl.sh start”
else
$CRUCIBLE_HOME/fisheyectl.sh start
fi
echo
[ $RETVAL = 0 ] && touch $pidfile
sleep 3
return $RETVAL
}
stop() {
echo -n $”Shutting down $prog: “
if [ “x$USER” != “x$CRUCIBLE_USER” ]; then
su – $CRUCIBLE_USER -c “$CRUCIBLE_HOME/fisheyectl.sh stop”
else
$CRUCIBLE_HOME/fisheyectl.sh stop
fi
echo
rm -f $pidfile
return $RETVAL
}
case “$1” in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 10
start
;;
*)
echo “Usage: $0 {start|stop|restart}”
esac
exit 0
Now make the script executable.
chmod +x /etc/init.d/fisheye
Then add the script as a service.
chkconfig –add fisheye
chkconfig fisheye on
After this has been done you can manually start or stop the service by using these commands:
service fisheye stop
service fisheye start
If you dare issue a reboot command and check if the application comes back up after rebooting (please make sure that your database is auto started as well). If you encounter a problem then you could check the log files in application its var folder. Maybe an extra line-feed was added to the script when you copied and pasted it (double check).
If the application is running then you should see it running under its own user:
ps -ef | grep java
Good luck! Please comment if you know ways to improve.
Currently I am setting up Confluence in a CentOs 5.4 environment. As I want it to start automatically when booting some figuring out had to be done. This procedure also works for Jira and Crowd by the way. Here are the results. FYI: we use Apache httpd and the Apache Tomcat connector to connect http daemon port 80 to our Tomcat port, this post will not dig into that subject.
For security reasons you’d want to run Confluence using a dedicated user with limited privileges. So we create a user called confluence. By default you cannot use this account to login, but we don’t need that.
useradd -m confluence
Now we make the user owner of the folders that Confluence is using (change the folder names to the names that you are using).
chown -R confluence /opt/confluence-3.1.1-std
chown -R confluence /var/confluence
When this is done we can test if the confluence user can stop and start Confluence. We use the su command to execute the scripts being the confluence user. First we shut Confluence down (assuming it is running already) and then we start it up again.
cd /opt/confluence-3.1.1-std/bin
su confluence -c ./shutdown.sh
su confluence -c ./startup.sh
It can take some time to get it back up, so be patient and hit F5 a few times in your browser. Also, take a look at the log files in the logs folder if you are unsure or need to know a bit more about what is going on or going wrong.
Now we have confirmed that we are able to start and stop Confluence using our dedicated user we will create a script that allows us to run Confluence as a service. This means we can start, stop and ask about its status like any other service. Use nano to create the script:
nano /etc/init.d/confluence
Now copy and paste the following script. Adjust folder names to match your own situation. As Confluence standalone comes with Tomcat integrated, it basically is an adjusted Tomcat script. Beware: the script might contain some linefeeds which you need to remove to have it run properly.
#!/bin/bash
#
# Startup script for Tomcat/Confluence
#
# chkconfig: 345 84 16
# description: Tomcat/Confluence server
# processname: confluence
#Necessary environment variables
export CATALINA_HOME=”/opt/confluence-3.1.1-std”
if [ ! -f $CATALINA_HOME/bin/catalina.sh ]
then
echo “Tomcat not available…”
exit
fi
start() {
echo -n -e ‘\E[0;0m'”\033[1;32mStarting Tomcat: \033[0m \n”
su -l confluence -c $CATALINA_HOME/bin/startup.sh
echo
touch /var/lock/subsys/confluenced
sleep 3
}
stop() {
echo -n -e ‘\E[0;0m'”\033[1;31mShutting down Tomcat: \033[m \n”
su -l confluence -c $CATALINA_HOME/bin/shutdown.sh
rm -f /var/lock/subsys/confluenced
echo
}
status() {
ps ax –width=1000 | grep “[o]rg.apache.catalina.startup.Bootstrap start” | awk ‘{printf $1 ” “}’ | wc | awk ‘{print $2}’ > /tmp/tomcat_process_count.txt
read line < /tmp/tomcat_process_count.txt
if [ $line -gt 0 ]; then
echo -n “confluenced ( pid “
ps ax –width=1000 | grep “[o]rg.apache.catalina.startup.Bootstrap start” | awk ‘{printf $1 ” “}’
echo -n “) is running…”
echo
else
echo “Tomcat is stopped”
fi
}
case “$1” in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 3
start
;;
status)
status
;;
*)
echo “Usage: confluenced {start|stop|restart|status}”
exit 1
esac
Because the script needs to be executed we have to allow execution:
chmod +x /etc/init.d/confluence
The final steps are to add the service and to switch it on.
chkconfig –add confluence
chkconfig confluence on
If all goes well you should be able to reboot and have a running Confluence instance when it finishes. Make sure that the other required services are running as well (database, httpd, ..). You can check and change their settings by using the setup command.
Please leave a comment if you’d like to suggest an improvement.
Less than a minute!
That’s what it took to get App Engine running locally and seeing the first page served in my browser!
All you need to do, is to add an extra source for software updates and select the Google App Engine. It’s all explained here.
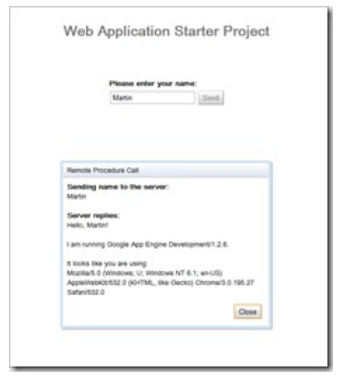
Long story short: Google App Engine is Google’s public application hosting service. You can run your own web application, databases, etc. on Google servers. It’s free for small applications.
Of course you could run your own server (either rent one or run one at home), but this means you have the maintenance problems, security issues and performance problems to deal with.
Unfortunately I have not been able to attend JFALL this year, there was a session which was about Google App Engine.
I have some ideas about using Google App engine. Currently I am thinking about using it to store data for my Android applications.
It’s definitely something I’m going to look into very soon.
This guy got a small Wicket application running on App Engine, cool eh!

For the last days I’ve been looking in to some products that a potential client is using and I have no experience with. There are three development process related products that nicely integrate together:
As they are commercial and all from the same company (Atlassian) it is no surprise that they integrate very well. Reports from Bamboo and Jira can be published via Confluence so that all essential information can be found in the same place – nice for both management and developers.
It is also possible to use Bamboo as a release management tool, somebody wrote a nice article about it and developed some plugins. This is about a year old, so maybe it is built in by now.
UnxUtils is a project that has ported common GNU utilities to Windows. This means that you can use Unix/Linux commands in your Windows dos shell! http://unxutils.sourceforge.net/